Nowadays, the production of data is colossal. Although figures for the year 2020 are not yet available, a study by BSA, available on the Microsoft corporate website, states that already in 2016, 2.5×1030 bytes of data were generated every day, with an increasing trend.

According to BSA, they are, among other things, the lifeblood of "economic growth, agricultural development, policy decisions and renewable energy management. Better management of the data produced, even if sensitive, can have a considerable impact. Indeed, Microsoft and General Electric mention that economists agree that improving data understanding and management by just 1% could increase international GDP by US$15 trillion. Thus, currently, 90% of large companies cite data as a key resource [1], justifying the emergence of the field of knowledge discovery with the objective of making sense of all this data.
Knowledge discovery is now applied in many and varied domains, such as manufacturing (with the emergence of industry 4.0), finance (with hedge fund algorithms), marketing (for the design of recommendation systems), fraud detection, astronomy...
There is sometimes confusion between the terms data mining and knowledge discovery.
The process of knowledge discovery is broader than data mining, which is only one step (though probably the most important one).
The domain of knowledge discovery is evolving along with the fields in which it intersects: machine learning, artificial intelligence, statistics, data visualization and optimization
As such, knowledge discovery focuses on the general process of knowledge extraction since it has been defined as "the non-trivial process of identifying valid, novel, potentially useful, and understandable regularities in data". In this sense, it extends the logic of statistics since, on the one hand, it aims to produce a language and a framework for inferring regularities from a sample to the overall population while producing metrics to quantify the uncertainty of these generalizations, and on the other hand it aims to automate the whole process including both the "art" of hypothesis selection and the analysis of the data. It is therefore not limited to the discipline of data mining, which will always find statistically significant regularities in large enough data sets, even in completely random data sets where any regularity is purely coincidental.
However, it should be noted here that the notion of "knowledge" has no philosophical pretenses.
Indeed, as presented in figure 1, if we consider the facts known by the system (the data), we qualify as information the regularities, i.e. the descriptions of agglomerations of these data, and as knowledge the significant and new information which exceeds a threshold of interest, the notion of interest as well as the threshold being fixed by the user, depending on the domain and the application.
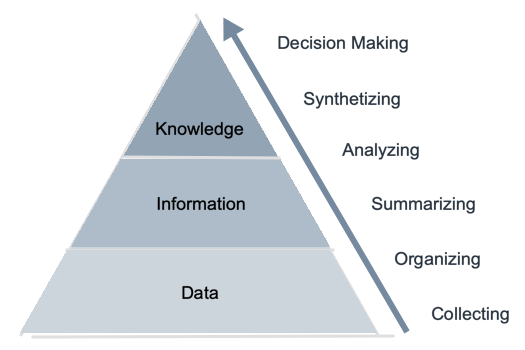
Figure 1
The general process of knowledge discovery is depicted in Figure 2. It is iterative and composed of 9 steps that may require backtracking at any time.
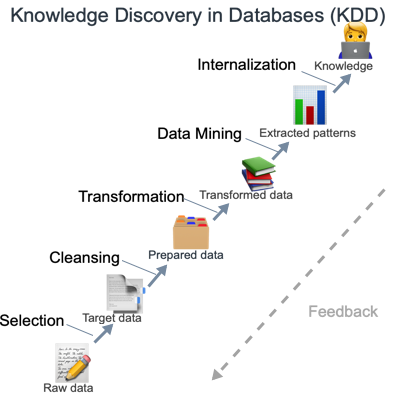
Figure 2
After defining a goal for the process (1), a data set is selected to be confronted with the process (2). The data are then cleansed (noise removal and missing values treatments) (3) and reduced if necessary (by PCA for example) (4). We then choose the data mining method corresponding to the objective (5) and the algorithm implementing this method in an optimal way according to the data (6). The application of the algorithm to the data (7) allows the extraction of regularities which are then filtered and interpreted (for example with the help of data visualization tools) (8). Finally, the extracted knowledge (9) can be used to refine the process, by integrating it in another system or simply in a documentation for a user (such as "dash boards").
As noted above, the process is highly dependent on the objective of the process. The three most widely used applications are:
To meet such objectives, there are multiple methods that we cannot cover exhaustively here. However, to give the reader an intuition of the main families of approach, they are roughly illustrated below:
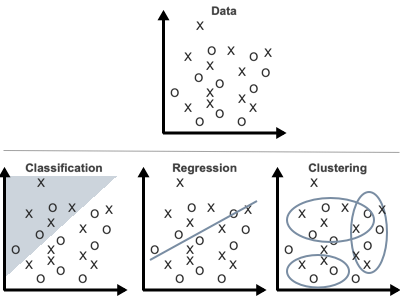
Figure 3
Classification consists in ordering data according to their similarities.
Regression is a statistical method that attempts to determine the type and strength of correlations between a given variable and a series of other independent variables.
Clustering consists of grouping together points that have common characteristics.
References:
[1] BSA. What’s the big deal with data? http://download.microsoft.com/documents/en-us/sam/ bsadatastudy_en.pdf, 2016. Accessed: 2020-04-17.
[2] Usama Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth. From data mining to knowledge discovery in databases. AI magazine, 17(3):37–37, 1996.
[3] Usama M Fayyad, Gregory Piatetsky-Shapiro, Padhraic Smyth, and Ramasamy Uthurusamy. Advances in knowledge discovery and data mining. American Association for Artificial Intelligence, 1996.
[4] G.E. Industrial internet: Pushing the boundaries of minds and machines. http://les.gereports. com/wp-content/uploads/2012/11/ge-industrial-internet-vision-paper.pdf, 2012. Accessed: 2020-04-17.
[5] Gary Smith and Jay Cordes. The 9 pitfalls of data science. Oxford University Press, 2019.